TinyBrain & Eye
There is a new project, and it is a perfect playground for an OCR software. It's called TinyBrain and it makes your computer listen to your commands.
I might write more about this.

There is a new project, and it is a perfect playground for an OCR software. It's called TinyBrain and it makes your computer listen to your commands.
I might write more about this.
I'm putting a new version (Alpha 10) out there. This version's major new feature: Character corrections are now associated to the original image which makes them much more persistent and easier to use. I hope it works as intended - if you encounter any problem, feel free to drop me a line.
Hey folks -
I'm a bit distracted by "real life" this week, i. e. non-computer development work. Various kinds of idiots are begging for my attention: idiot landlords and their idiot representatives, idiot politicians and evil idiot bureaucrats. And to top it all off, some neighbors who feel they need to be obnoxiously loud every other day.
These conflicts are actually more than just local: they have a global dimension. The Idiot People who are representatives of the Old Empire feel (rightly) that their high time is ending.
Yeah. I'm winning all these fights, so no reason to worry. I'd love all that crap to end soon though, it's just obnoxious. (Did I use that word before?)
On the technical side, despite the nonsense listed above, there is still quite some progress. I've put out two new releases since the last post (Alpha 9 and Alpha 9+). The latter is an unannounced intermediate version that I put up there for a user who requested support for Hungarian accents. Unannounced or not, people are downloading it happily... (and why shouldn't they).
I'll also put the Hungarian accents into Alpha 10 and, to make it a true bilingual release, throw in some German umlauts too. Generally, Eye is now Unicode-enabled so it basically supports any language (any language loosely based on Latin characters).
Finally, I saw Eye referenced on the web in a few places. One of them actually shows Mac OS X screenshots, so I think we can now safely call Eye "Mac OS X-compatible".
A new release for you folks to play with!
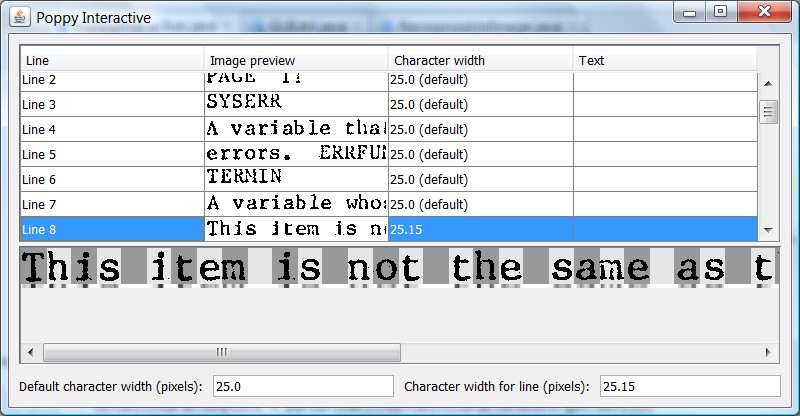
I have been busy studying this example text. Out came a new recognizer specialized on typewriter fonts. Letter recognition has some room for optimization, but in the area of segmentation, the new engine is doing extremely well. All you have to do is give it an estimate of how big the letters are (character width in pixels). With that information in mind, the segmenter automatically adjusts itself as it scans the line so it always stays sharp. It is also not fazed by difficulties like little dirt pixels or letters that touch each other.
To improve this even further, I have a plan for calculating the character width automatically, so recognition can be done without any manual input.
Eye's user interface has also been improved. You can now right-click on any unrecognized character and correct it right away. You can then save the corrections you made and they will appear in the list as a new recognizer. This way, recognition accuracy will go up steadily. For the near future, I am planning to further simplify this process by allowing users to correct whole words at a time.
I am also happy to report that public interest in the software is rising nicely, with more and more downloads per day. Unfortunately, the first donation I reported turned out to be a dud (the person did not follow through with payment). However, the PayPal problem I reported has been solved and I expect no further difficulties in that area, so if you decide to make a donation, I promise it will have safe passage until it arrives at my place. :)
One of the multiple entities I am currently fighting is the company called PayPal. For completely bogus reasons, they locked me out of my account, rendering more than € 50 inaccessible. According to their procedures, I can only resolve this by calling their insanely expensive hotline. I cannot and will not do that.
However, after I wrote them some very angry mails (this really helps!), it now seems that they will call me, so the issue can be solved without me paying anything.
Which is good because I just found out that I received my first donation for Eye! Funnily, I don't know who made it nor how much it is (because of the blocked PayPal account). Either way, it makes me happy. Keep it coming folks!
In other news, I was contacted by a friendly fellow who maintains a large archive of scanned historic documents. All computer-related: programs, manuals et cetera. Turns out off-the-shelf OCR doesn't perform too hot on these documents. This might well be a great opportunity for Eye to step in and save the day.
The least I can say is: The data in there is already motivating me to write some new code and tackle some new input. Behold this screenshot!
The integrated process which is my life is progressing on several fronts. I am cleaning up some relations to people I used to be friends with, advancing the search for a new apartment (and the interesting question of how to move there with no money), figuring out how to get my teeth fixed (with no money) and, when all that worldly nonsense calms down for a moment, cooking up a new algorithm for Eye.
Recently, Eye became sophisticated enough to recognize an example of real scanned text with only a few errors - well enough to consider this a success. The scan quality in this example is very good which allows employing a two-stage approach: segment first (separate letters from each other), then recognize each letter individually.
Now I'm moving on to a harder example. This one has low resolution, is blurred and letters are very close to each other. A classical segment-then-recognize process is likely to fail here as it is hard to tell letters apart without putting in some knowledge about what is a letter and what is not.
To solve this, segmentation and recognition must become one. I am working on a new algorithm based on this premise, and there is working code already. Behold:

Here, the letters "HALLO" were recognized as "idALi:O" (original text is shown in black, recognized text in red with gray outline). Of course that's not a perfect result yet, but upon closer inspection 3 of the 5 letters are actually correct. The algorithm's creative re-interpretations of the other two letters are not totally random either: They cover most of the real letters' black pixels. Of course, they also add some extra black (i.e., red) pixels.
Bottom line: With some more fine-tuning and a semi-automated training process, we might be seeing a powerful new recognition algorithm for challenging input images developing here.
In case you didn't notice yet: Planet Earth is in transition. Some things are going away. (And new things appear.)
The transition is great because it will make Earth a much better place. The problem, however, is that people still rely on some of the things that are dying.
Here's an example. This week, I recorded two video tutorials for Eye:
ScreenToaster's problem
ScreenToaster.com, the site I used to make the videos, is basically a nice tool. The problem is: It seems to be going away. They don't say this on their homepage, but a few observations strongly support that conclusion. For one, their forum is full of spam. And there is a report about their closing down. That report is not entirely accurate though as the alleged closure date has passsed and the screentoaster site is - technically - still up.
Anyway, what's stupid is that the second video I made is now locked into screentoaster.com and there is no apparent way to download it and upload it somewhere else.
Things with a future this uncertain should probably better be avoided.
Unfortunately, one of the things with a more than uncertain future is the place I currently reside in. They call it "Germany".
Why Germany sucks
Germany is, at its core, an unlikable and vile country, relying on war and aggression as a means to "live". Germany's worst feature is its women: They are completely horrible all around. Their sexuality is close to non-existent. It is better having no woman at all than (God forbid) giving one of these hellish beasts an opportunity to ruin your life.
In short: Today's Germany has no future.
What's next
It's clear that I will leave this place. So the question is: Where do I go? Second question: How will I get there? Third question: How will I sustain myself there?
Well. Here's the good thing. I know that God has answers to these questions. That's why I'm not worried. I do would like to know everything right now; but if I don't, it's also ok because then that serves some purpose. If God isn't talking yet, it just means he needs to prepare the recipients first. Because God is not slow, nor is he mute. He has a good plan and he will reveal it just in time.
It better be anyway because it looks like I have to leave my apartment sometime this month, and I don't have a new place yet. But not to worry. Because one thing I know is that I am going UP, not down.
It features:
Some of the parts aren't fully integrated, for example the new segmenter is only used for the test cases, not for recognizing user images. But that is only a few more lines of code away!
...LOL :)
I'd say that's nice for a start. Wait and see what happens when recognition becomes really good. (And it will - just a matter of time.)
Progress is still amazing - even though I took a few hours "off" yesterday evening. I love it when a project has its own drive. You feel how it attracts you, enchants you, takes hold in you. You don't "work" on the project. You just enter a state of trance and watch how the miracle unfolds without the slightest effort or force.
This is such a project.
Eye: The Miracle Project™ =)
Here's what's new in Alpha 4:
It's good to have all this basic stuff in place - to have an OCR application that is ready for practical use. Because then we're ready for the next phase, and that's when it gets interesting.
INTRODUCING: THE OPEN RECOGNITION FRAMEWORK
You see: Eye's most remarkable feature is one that I haven't even talked about yet.
Eye contains what you could call an open recognition framework. That means that it is very easy to drop new algorithms into the system. Each new algorithm improves the system's recognition quality. This may include algorithms for tackling individual strains of difficult input as well as general-purpose, adaptive learning algorithms.
Workhorses + specialists = optimum result. =)
In the learning phase, there is an internal competition between the available algorithms. Each algorithm gets a shot at producing a custom-built recognition function for the problem at hand. Recognition functions can also be combined into a single function with superior accuracy. The best function that emerges from all of this mayhem is saved and used as the primary recognizer.
Thus: There is basically no limit to how good Eye can become. In due time, I expect to write a little tutorial showing how you can add your own algorithm to Eye. It's very easy, you just write some straight-forward Java code. For the core class of the current engine ("SegmentSignature"), there are only about 50 lines of interface code. Plus the actual algorithm, which, incidentally, is less than 40 lines long. Compact stuff!
Eye is progressing rapidly these days.
The project was only started this week and now here's the third release already. And these are not petty releases.
It is like "it wants to be", to adapt a quote from Mr. David Lynch. (He said that about the concept of "Twin Peaks" and his process of writing it.)
The new release achieves greatly improved accuracy when learning multiple font sizes at once. It's now typical to see 99-100% accuracy, even with "crazier" fonts.
It has to be said though that the overall engine is not perfect yet - its segmentation phase, primarily, is kinda basic. It does work when the font has enough space between letters.
{kind=link}
{kind=link}
{kind=link}
{kind=link}